NoSql
Appunti tradotti e riadattati del Prof. Pietro Colombo http://www.dicom.uninsubria.it/~pietro.colombo/
Indice
Slide14
Aggregation Pipeline
A framework for data aggregation based on data processing pipelines.
Documents enter a multi-stage pipeline that transforms them. Pipeline stages do not need to produce one output document for every input document.
Stages can:
- generate new documents
- filter out documents
MongoDB provides the db.collection.aggregate() method in the mongo shell. Pipeline stages appear in an array.
Documents pass through the stages in sequence. Stages can appear multiple times in a pipeline.
>db.collection.aggregate( [ { <stage> }, ... ] )

Main aggregation stage operators
$match: Select the documents to pass unmodified into the next pipeline stage. For each input document, outputs either one document (a match) or zero documents (no match).
$project: Reshapes each document in the stream E.g., add new fields or remove existing fields. For each input document, outputs one document.
$unwind: Deconstructs an array field from the input documents to output a document for each element. Each output document replaces the array with an element value. For each input document, outputs n documents where n is the number of array elements (n=0 for an empty array).
$group: Groups input documents by a specified identifier expression and applies the accumulator expression(s), if specified, to each group. Consumes all input documents and outputs one document per each distinct group. The output documents only contain the identifier field and, if specified, accumulated fields.
$sort: Reorders the document stream by a specified sort key. The documents remain unmodified. For each input document, outputs one document.
$limit : Passes the first n documents unmodified to the pipeline where n is the specified limit. For each input document, outputs either one document (for the first n documents) or zero documents (after the first n documents)
$skip: Skips the first n documents where n is the specified skip number and passes the remaining documents unmodified to the pipeline. For each input document, outputs either zero documents (for the first n documents) or one document (if after the first n documents).
$match
Filters the documents to pass only the documents that match the specified condition(s) to the next pipeline stage.
Syntax: { $match: { <query> } }
Example:
collection articles
{ "_id" : ObjectId("512bc95fe835e68f199c8686"), "author" : "dave", "score" : 80, "views" : 100 }
{ "_id" : ObjectId("55f5a192d4bede9ac365b257"), "author" : "ahn", "score" : 60, "views" : 1000 }
>db.articles.aggregate( [ { $match : { author : "dave" } } ] );
$project
Reshapes each document in the stream
Syntax: { $project: { <specifications> } }
Specifications:
- <field>: <1 or true> Specify the inclusion of a field. [if the field does not exist no inclusion is performed ]
- _id: <0 or false> Specify the suppression of the _id field.[only achievable with _id]
- <field>: <expression> Add a new field or reset the value of an existing field.
{
"_id" : 1,
title: "abc123",
isbn: "0001122223334",
author: { last: "zzz", first: "aaa" },
copies: 5
}

$unwind
Deconstructs an array field from the input documents to output a document for each element.
Prototype form: { $unwind: <field path> }
E.g., collection inventory includes the document
{ "_id" : 1, "item" : "ABC1", sizes: [ "S", "M", "L"] }
> db.inventory.aggregate( [ { $unwind : "$sizes" } ] )
Restituisce:
{ "_id" : 1, "item" : "ABC1", "sizes" : "S" }
{ "_id" : 1, "item" : "ABC1", "sizes" : "M" }
{ "_id" : 1, "item" : "ABC1", "sizes" : "L" }
$group
Groups documents by some specified expression and outputs to the next stage a document for each distinct grouping.
Prototype: { $group: { _id: <expression>, <field1>: { <accumulator1> : <expression1> }, ... } }
- _id specifies the mandatory grouping key
- <accumulator> specifies the aggregation operation
{"$group" : {"_id" : "$author", "count" : {"$sum" : 1}}}
Main accumulator operators
$sum Returns a sum for each group. Ignores non-numeric values.
$avg Returns an average for each group. Ignores non-numeric values.
$first/$last Returns a value from the first/last document for each group. Order is only defined if the documents are in a defined order.
$min/$max Returns the lowest/highest expression value for each group.
$push Returns an array of expression values for each group.
$addToSet Returns an array of unique expression values for each group. The order in the array is undefined.
$group example, collection sales:
{ "_id" : 1, "item" : "abc", "price" : 10, "quantity" : 2, "date" : ISODate("2014-03-01T08:00:00Z") }
{ "_id" : 2, "item" : "jkl", "price" : 20, "quantity" : 1, "date" : ISODate("2014-03-01T09:00:00Z") }
Calculate total price and avarage quantity by date
>db.sales.aggregate( [
{$group :
{ _id : { month: { $month: "$date" },
day: { $dayOfMonth: "$date" },
year: { $year: "$date" } },
totalPrice: { $sum: { $multiply: [ "$price", "$quantity" ] } }, averageQuantity: { $avg: "$quantity" }}}
])
Slide15
Indexes
Gli indici sono la chiave per migliorare le prestazioni su MongoDB;
senza indici MongoDB deve scansionare ogni documento in una raccolta per selezionare i documenti corrispondenti.
Gli indici sono memorizzati in alcuni campi in una forma facilmente accessibile.
I valori degli indici sono memorizzati ordinatamente. Gli indici sono definiti per collezione.
Scopo:
- Velocizzare le query comuni
- Ottimizzare delle specifiche query
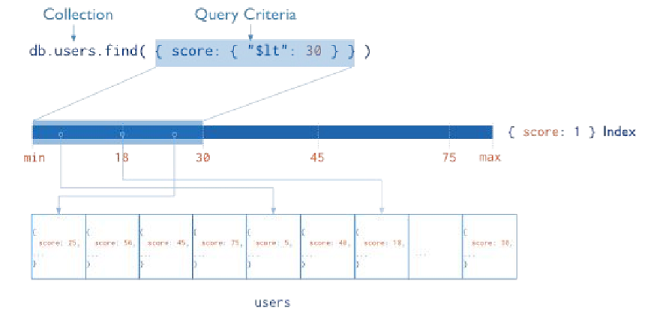
L'indice può essere attraversato da destra a sinistra o viceversa per restituire risultati ordinati (senza bisogno di essere ordinato)
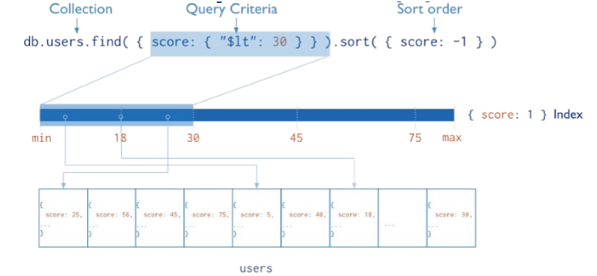
Eseguendo una query Mongo non ha bisogno di ispezionare i dati se sono tutti compresi nell'indice
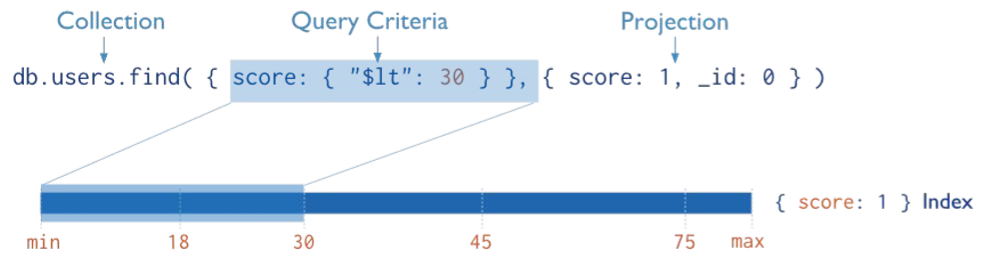
Index Types
- Default: _id
- Esiste di default, quindi se non e specificato _id, è creato
- Unico
- Singolo campo
- Definito dall'utente, su un singolo campo di un documento
- Compound
- è definito dall'utente su più campi
- Multikey index
- Per indicizzare il contenuto di un arrey
- Crea indici separati, per ogni elemento dell'arrey
- Ordered Index
- Hash Indexes
- Fast O(1) è un indice molto veloce e indicizza l'hash di un campo;( vale solamente per quando cerco valori uguali)
- Geospatial Index
- 2d indexes = use planar geometry when returning results ■ For data representing points on a two-dimensional plane
- 2sphere indexes = spherical (Earth-like) geometry, For data representing longitude, latitude
- Text Indexes(per cercare stringhe contenute in una collezione)
explain
Il comando explain() può essere usato per "vedere" come MongoDB usegue la query
> db.users.find({username: "user101"}).explain("executionStats")
{
..."totalDocsExamined" : 1000000, //number of accessed documents
... "nReturned" : 1, //number of documents composing the result
..."millis" : 721, //execution time
}
Indice su un singolo campo
Permette di ottimizzare query simili, per creare un indice su un singolo campo ad es. con 'username'
> db.users.createIndex({"username" : 1})
Una volta che l'indice è stato creato e ripetendo le query:
>db.users.find({"username":"user101"}).explain("executionStats")
> db.users.find({username: "user999999"}).explain("executionStats")
Abbiamo un gran differenza di tempo di esecuzione. Questa velocità ha il suo prezzo:
- Ogni scrittura impiegherà più tempo di esecuzione...
- Gli indici devono essere aggiornati ogni volta che i dati cambiano
Si possono creare fino a 64 indici per ogni collezione,
ma sono raccomandati di non usarne più di 2
Quali campi usare come indice? Bisogna analizzare le query di quella particolare applicazione
Un indice tiene tutti i suoi valori ordinatamente:
- ordinare i documenti che sono indicizzati è molto più veloce
- useful for sorting only if it is a prefix of the sort
Non è utile per ordinare composti da più chiavi:
> db.users.find().sort({"age" : 1, "username" : 1})
Questa query ordina per età e username …
Indici composti
Un indice composto da più di un campo, è utile quando abbiamo query che devono ordinare tra più campi
Ad es. un indice composto era ottimizzato per la query precendente:
> db.users.createIndex({"age" : 1, "username" : 1})
L'indice potrebbe assomigliare a qualcosa del genere:
- [0, "user100309"] -> 0x0c965148
- …
- [1, "user100156"] -> 0xf78d5bdd
- [1, "user100187"] -> 0x68ab28bd
- …
- [2, "user100141"] -> 0x3996dd46
- [2, "user100149"] -> 0xfce68412
- …
Ogni riga dell'indice specifica età e username e punta ad un documento. Il modo in cui poi viene calcolatò l'indice dipende dal tipo di query
Point query
>db.users.find({"age" : 21}).sort({"username" : -1})
Quando cerco per dei documenti per un singolo valore, ma tanti documenti hanno quel valore
- Visto che è un campo secondario nell'indice,
i risultati sono già ordinati
- Non c'è quindi bisogno di ordinarli
- Indipendenza dalla direzione dell'ordinamento
Multi value query without sort
>db.users.find({"age" : {"$gte" : 21, "$lte" : 30}})
Quando cerco dei documenti che devono soddisfare più condizioni
Il primo indice "age",è usato per ritornare i valori che soddisfano la condizione
[21, "user100000"] -> 0x37555a81
[21, "user100069"] -> 0x6951d16f
...
[30, "user999775"] -> 0x45182d8c
[30, "user999850"] -> 0x1df279e9
Grazie all'indice secondario i documenti sono già ordinati (per username)
>db.users.find({"age" : {"$gte" : 21, "$lte" : 30}}).sort({"username" :1})
L'indice potrebbe assomigliare a qualcosa del genere:
[21, "user100000"] -> 0x37555a81
[21, "user100069"] -> 0x6951d16f
...
[22, "user100004"] -> 0x81e862c5
[22, "user100328"] -> 0x83376384
...
Visto che vogliamo i dati ordinati per username ma vengono restituiri dalla prima parte della query
per età, l'ordinamento avverà in memoria.
Query Selectivity
"Query selectivity" è la misura di quando i predicati estraggono i documenti da una collezione
Is an expression that evaluates to TRUE, FALSE, or UNKNOWN. Predicates are used in the search condition of WHERE clauses and HAVING clauses, the join conditions of FROM clauses, and other constructs where a Boolean value is required.
è una misura utile per capire se una query usa gli indici efficacemente.
Più una query è selettiva minore sarà la percentuale di documenti.
ad esempio una query che ricerca l'_id del documento sarà molto selettiva
Query poco selettive che trovano una grande quantità di documenti, non usano gli indici efficacemente
Ad esempio gli operatori $nin e $ne solitamente trovano una gran quantità di documenti; spesso indici su indici che usano
$nin e $ne non portano a migliori performance, in quanto cercano in tutti i documenti.
La selettività di un espressione regolare dipende dalla espressione regolare
Covered Query
Un indice copre una query quando:
- tutti i campi della query fanno parte dell'indice
- tutti i campi selezionati fanno parte dello stesso indice
ad esempio una collezioni di prodotti che ha il seguente idice:
>db.inventory.createIndex( { type: 1, item: 1 } )
Questo indice copre la seguente query
>db.inventory.find({ type: "food", item:/^c/ },{ item: 1, _id: 0 })
Quando l'indice contiene tutti i campi della query:
- Mongo può trovare subito le condizioni che soddisfano la query usando solamente l'indice
- Viene eseguita molto più rapidamente che cercando fuori dall'indice
Restrictions on Indexed Fields
Un indice non copre una query quando:
- qualsiasi dei campi di un indice in qualsiasi documento include un arrey
- any of the indexed field in the query predicate or returned in the projection are fields in embedded documents.
es. considera una collezione con la seguente struttura:
{ _id: 1, user: { login: "tester" } }
La collezione ha un indice: { "user.login": 1}
L'indice non copre la seguente query:
db.users.find( { "user.login": "tester" }, { "user.login": 1, _id: 0 } )
Comunque, la query può usare { "user.login": 1 } l'indice per trovare i documenti
Quando non creare un indice
Gli indice sono più efficaci se coprono una piccola quantità di dati,
sono meno efficaci quando vengono usati sulla maggior parte dei dati
Per assurdo se una query deve prendere tutti i dati da una collezione, l'esecuzione sarà più lenta di scansire tutta la collezione perchè
gli indici hanno bisogno di 2 lookups
- Guardare tutto l'indice
- Seguire il puntatore dell'indice nel documento
La scansione completa comporta solamente la scansione dell'intero documento
Non ci sono regole per determinare quando un indice aiuta o è di ostacolo, ci sono troppe variabili
size of data, size of indexes, size of documents, average result set size
Se una query ritorna più del 30% dell'intera collezione si può iniziare a vedere se è più efficente una semplice scansione nella collezione
Slide16
Data modeling Column family datastores
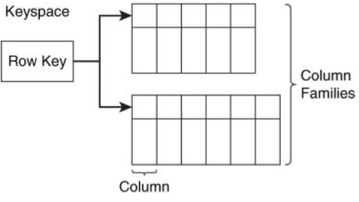
Le strutte di un Data modeling Column family sono:
- Keyspace
- Row key
- Column
- Column family
Keyspace
è la radice, i contenitore che contiene i column families, row keys, e related data structures
Tutti le altre strutture sono contenute in Keyspace
Di solito c'è un solo Keyspace per applicazione
Row key
L'indentificativo di una riga in un column family
Ha la stessa funzione di della chiave primaria in un db relazionale
è usato per partizionare e ordinare i dati:
- In HBase, rows are stored in lexicographic order
- In Cassandra, rows are stored in an order determined by the partitioner

Column
A data structure for storing a single value:
- Values may be simple string of bytes (e.g., HBase) as this does not require data types validation
- Values may refer to data types ranging from integers and strings to lists and maps. (e.g., 20 data types Cassandra).
Characterized by:
- A column name
- A time stamp or other version stamp (Allows the database to store multiple values associated with a column while maintaining the ability to readily identify the latest value. different types of version control mechanisms used)
- A value
A column, along with a row key and version stamp, uniquely identifies values

Column family
Collections of related columns, Columns that are frequently used together should be grouped into the same column family
Column families are stored in a keyspace. Each row in a column family is uniquely identified by a row key. Similar to tables within RDBMSs, but:
- RDBMSs do not necessarily maintain an order within tables
- Within RDBMSs all tuples have the same columns
es. Store multiple rows and multiple columns
Design strategies
Il design di come modellare le tabelle si basa sulle query.
Sono loro infatti che forniscono le informazioni necessarie per modellare un Column family
1) Entità: sono modellate come righe, identificate da un RowKey
2) Attributi delle entità: Sono modellate come colonne (riferite dalle query di selezione e proiezione)
Query criteria:
- Il criterio di selezione ci suggerisce come organizzare i dati in tabelle e partizioni
- Il criterio di selezione ci suggerisce come raggruppare gli attributi nei colum families
Valori derivati, possono essere ulteriori valori che vogliamo salvare
Differenze con il RDBMSs.
Column family sono implemetati differentemente:
- Column family databases sono implementati come mappe multidimensionali scarsamente popolate
- Columns possono cambiare tra le varie righe
- Columns possono essere aggiunte dinamicamente
- Joins non sono usati, si usa la denormalizzazione
Guide linea per modellare le tabelle
Joins non sono usati, si usa la denormalizzazione
Usare la tecnica "valueless colums". (The name of your column becomes the relevant information & the value of the "name/value" pair is empty)
Usa sia il nome della colonna che il valore per salvare i dati
Modellare un entità come una singola riga
Mantenere un appropriato numero di "column value versione"
Evitare dati complessi in "column values"
Denormalizzazione
Le tabelle modellano le entità. è prevedibile avere una tabella per entità
Solitamente colums store necessità di meno tabelle, visto che la denormalizzazione ci permette di evitare i join
Una relazione MoltiAMolti nei database relazionali necessita di 3 tabelle
- 2 per le entità
- una per rappresentare la relazione tra esse
Una singola tabella può essere usata nei colum family
Es. Cust_Prod tiene traccia della relazione tra utenti e prodotti
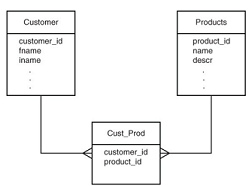
Many to many relations
A set of column names referring the purchased products

Products include a list of customer IDs specifying the customers who bought the product
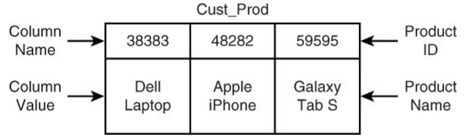
Solution 1 valueless columns
Instead of having a column 'ProductPurchased1' with value 'PR _ B1839', the table stores the product ID 'PR _ B1839' as the column name. No need for associated values
Using column names to store data can have advantages:
In Cassandra, data stored in column names are stored in sort order, but data stored in column values are not.
A value may be associated with a column name ○ E.g., the presence of property (T, F)
Solution 2 - column names and values
Use the column value for denormalization
Example. Product features like description, size, color, and weight in the products table
To list products bought by a customer → add the product name as column value, in addition to its identifier, specified as column name
No need to join the tables to produce the report
esempio fatto bene
Abbiamo un sistema relazionale modellato come nell'immagine:

Vorremmo fare queste query:
- Tutti gli utenti a cui piace quel particolare oggetto
- Tutti gli oggetti che piacciono a quel particolare utente
Ci sono 2 modi per denormalizzare la relazione in un ColumFamily datastore
1) denormalizzare le entità con un indice personalizzato
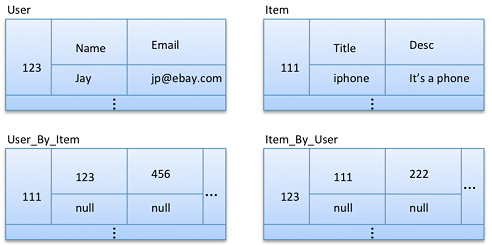
2) Normalizzare le entità con una denormalizzazione in un indice personalizzato
 Slide18
Slide18
Modellare entità
Porta ad avere righe con diverse colonne
- I prodotti nel nostro esempio hanno delle caratteristiche in comume (ID,price,SKU)
- I prodotti però hanno tra di loro differenti attributi
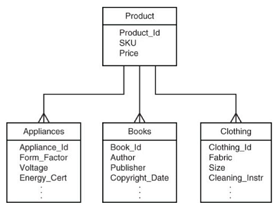
Attributi in tabelle differenti
I column family datastore non hanno lo stesso livello di controllo delle transazioni dei DB relazionali
Di solito infatti la scrittura di una riga avviene in maniera atomica, quindi se dobbiamo fare un update di più colonne o tutte andranno a buon fine oppure nessuna
Un upload a più tabelle può quindi portare ad inconsistenza nei dati
es supponiamo che vogliamo aggiornare la tabella dei prodotti e la tabella dei libri
Se l'update nella tabella dei prodotti viene completata con successo mentre quella nella tabella libri fallisce si avrà → inconsistenza
Hotspotting in row keys
Hotspotting capita quando tante operazioni sono eseguite su un ristretto numero di nodi, mentre il resto dei cluster è poco utilizzato
HBase usa un ordinamento lessografico per ordinare le rowKey. Ciò permettte:
- Diminuire le latenze sul disco
- Può portere a continuare a usare sempre lo stesso nodo mentre gli altri sono sotto-utilizzati
Column value versions
Alcuni database, come HBase, permettono di salvare più versioni dello stesso valore. I valori sono
- Timestam, così si riesce a determinare facilmente l'ultima modifica
- Utile per tornare ad una situazione precedente
As many versions as requirements dictate, but no more
HBase permette di fissare un numero di versioni da tenere in memoria, implemetando un buffer circolare
HBase:
- Ogni valore è associatp con il proprio timestam
- Più versioni
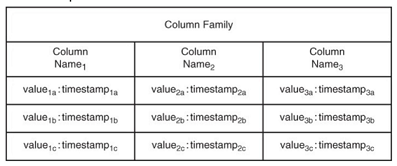
No complex data structures
I column data family permettono di salvare oggetti Json, ma non è consigliato; consigliato quindi usare la stringa
Se invece si deve effettuare qualche operazioni sull'oggetto, meglio decomporre la struttura
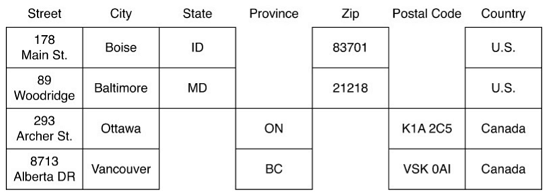
Separate columns per attribute:
- allow using column families
- Favor the use of secondary indexes
Meglio separare in colonne: strada città, stato, zip e permettere la definizione di un indice secondario

Guidelines for indexing
Gli indici permetto rapidamente di fare un lookup dei dati in tabella
SELECT fname, lname FROM customers WHERE state = ‘OR’
Gli indici permettono di recuperare le informazioni più velocemente, questa miglior performance viene raggiunta con un incremento dello spazio occupato
Index types
Gli indici primari sono sulla rowKey di una tabella, e sono automaticamente mantenuti dal sitema
Gli indice secondari sono creati su una o più colonne
- Sia direttamente il DB o l'utente può creare e gestire gli indici secondari
- Non tutti i DB forniscono la possibilità di avere un indice secondario gestito dal sistema
you can create and manage tables as secondary indexes in all column family database systems
Automatically managed indexes
Richiedono minor codice per essere mantenuti. Es in cassandra il codice:
CREATE INDEX state ON customers(state)
- Crea un indice
- Mantiene tutte le necessarie strutture
- Determina l'uso ottimale dell'indice
Per esempio nella seguente query, ipotizzando di avere come indice "state" e "Iname":
SELECT fname, lname FROM customers WHERE state = ‘OR’ AND lname = ‘Smith’
Cassandra scegli che indice usare per primo, di solito usa il più selettivo
Nel nostro esempio con 15000 persone in oregon e 200 chiamate Smit scegliera prima di usare l'indice sul nome
Bisognerebbe evitare di usare un indice (o fare dei test) se:
- C'è un ridotto numero di valori unici nelle colonne
- Ci sono tanti valori unici in una colonna
- I valori nella colonna sono pochi
Example 1. In una colonna ci sono un numero quasi uguale di si e no
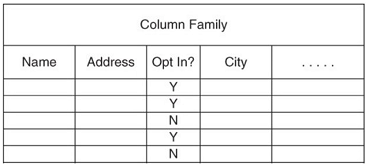
Esempio 2. Non porta benefici se la cardinalità è troppo alta, ad esempio nella colonna mail. Più efficiente usare una ricerca su tutta la colonna senza indice
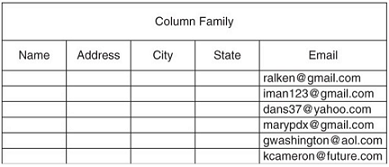
Esempio 3. Non utile se molti utenti non usano quella colonna
- Quasi tutti gli utenti vivono in US ed hanno la provincia
- Gli utenti canadesi non hanno la colonna della provincia
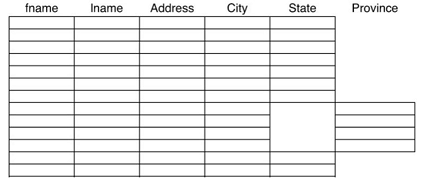
Indexes managed using tables
é utile quando
- il column family non supporta automaticamente l'indice secondario
- la colonna da indicizzare ha molti valori distinti
Richiede tabelle che le tabelle che salvano i dati siano accedute trami l'indice
Example
Indice che supporta queste query
- Lista di tutti gli utenti che hanno comprato un particolare prodotto
- Lista di tutti
Slide19
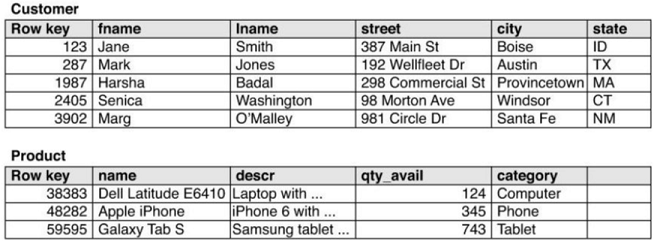
Indexes managed using tables
è utile quando:
- quando il colums family non supporta automaticamente l'indice secondario
- la colonna da indicizzare ha molti valori unici
Richiede che la tabella dove sono salvati i valori sia acceduta tramite l'indice
The indexes refer to the same table, column family, and column data structures used to store your data.
Esempio 1. Indici che supportano queste query:
- Lista di tutti gli utenti che hanno acquistato un particolare prodotto
- Trovare tutti gli utenti che hanno acquistato quel particolare prodotto
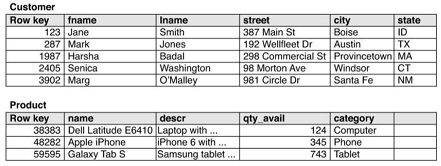
Scopo:
- trovare subito le informazioni di uno specifico prodotto (name and description)
- Trovare i clienti che hanno comprato quel prodotto
Strategia:
- Una tabella che usa prodoctID come rowKey. Come nome della colonna l'ID del cliente
- Il valore della colonna può salvare informazioni aggiuntive come il nome fname
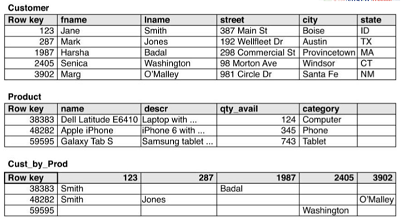
Esempio 2 Elencare tutti i prodotti acquistati da un utente
- il userID sarà il nostro rowKey
- prodotto ID sarà indicato tramite il nome della colonne
Il valore della colonna invece salverà il nome del prodetto
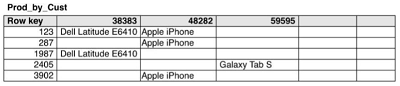
Indexes managed using tables
L'utente è responsabile di tenere aggiornato l'indice
2 strategie
a. aggiornare l'indice ogni volta che c'è un cambiamento nei dati. (es quando un cliente acquista qualcosa)
- pro: l'indice è aggiornato sempre
- contro: lunga latenza se più scritture avvengono nello stesso momento
b. avere un job che ad intervalli regolari aggiorna l'indice
- Pros: non incrementa la latenza
- Cons: ci possono essere dei periodi in cui indice e dati non sono sincronizzati
Le scelte sono dettate anche dalle specifiche
a. When queries are executed
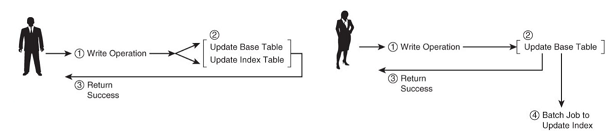
Slide19b
Principi nella distribuzione dei dati e consistenza
La scalabilità in un sistema
Scalabilità significa poter gestire un continuo aumento dei dati e delle query senza perdere in performance.
Ci sono 2 possibili approcci
Scalabilità verticale
Implica grandi e più potenti mezzi hardware:
- Più grandi e capienti dischi
- Usare architetture parallele
- Più grandi memorie
è la scelta tradizionale, favorisce una forte consistenza dei dati ed è semplice da realizzare.
Ha però:
- Costi alti (un supepr-server costa più che un computer con "hardware base")
- Dati hanno un limite (lavorano bene finche i dati sono entro una certa soglia)
- Previsioni (all'inizio dello sviluppo non si sa effettivamente la grandezza finale)
- I costi per l'hardware sono immediati nella scalarità verticale
- Solo pochi costruttori di hardware per "super-server"
Scalabilità orizzonale
Nella scalavilità orizzonale il sistema è distribuito su più macchine/nodi
Ongi macchina può avere un hardware relativamente economico
Nell'approccio orizzonale:
- I dati sono partizionati in più dischi
- L'applicazione può usare la memoria di tutte le macchine
- Modello computazionalmente distribuito
Il modello verticale introduce nuovi problemi: sincronizzazione, consistenza, errori parziali, ...
Le tipiche false ipotesi che si hanno su di un sistema distribuito sono:
- La rete si affidabile
- La latenza è zero
- La banda sia infinita
- Il network sia sicuro
- Il network si omogeneo
- La topologia della rete non cambia
- Ci sia solamente un amministratore
Ci sono 2 modi per distribuire i dati
Replicazione: lo stesso dato è copiato più volte in più nodi, master e slave - peer to peer
Sharding: il dato è spezzato in "data chunks" ed è sparso in diversi nodi
Questi 2 modi si possono usare insieme oppure combinarli
Server singlolo
Far girare il database su una singola macchina è sempre il miglior scenario, infatti evita un sacco di problemi
Può quindi avere senso usare un database NOSQL su un singolo server:
- Flessibilità dei dati, semplicità
- Per i "graph database" il grafico è difficile distribuirlo so più nodi.
Sharding (data partitioning)
è la possibità di poter avere parti di dato in differenti server.
Differenti persone possono accedere a differenti parti del dataset
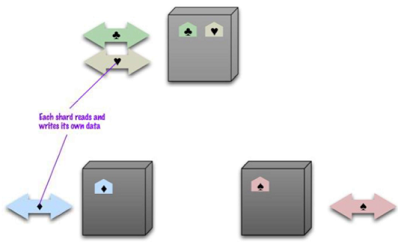
Possibilità di avere un "Auto" o "Manual" sharding
Ci sono 3 modi per distribuire i dati
Range sharding
Si partizionano i dati con valori coninui ed ordinati
Utile per fare "range-query"
Richiede:
- Coordinamento attraverso un master che gestisce gli assegnamenti
- Individuare e risolvere gli "hotspots"
Hash sharding
Il dato viene assegnato allo shard in base alla funzione di hash derivata dalla chiave primaria
Non ci vuole coordinamento
Permette un semplice lookup, di contro però non permette range query
Entity group sharding
Partiziona i dati con l'obbiettivo di abilitare una transizione su di una singola partizione di dato "co-locate"
Raccomandazioni
Bisognerebbe che:
- Dati a cui si accede contemporaneamente siano tenuti insieme, l'utente può trovare quello che cerca in un singolo nodo
[Aggregate data model aiutara a raggiungere questo obbiettivo]
- Organizzare i dati nel nodo in base alla posizione fisica e al carico di lavoro
La caduta di un nodo provoca i dati dello shard inraggiungibili, per questo che viene spesso combinato con la replicazione
Strategie di replicazione
Possiamo avere 2 variabili: "Quando" e "Dove". Quando gli update sono propagari alle repliche e dove gli update sono accettati.
Quando
Eager (sincrono) propaga immediatamente i cambiamenti a tutte le sue repliche prima che la risposta sia data al client
Consistenza del dato contro una alta latenza
Lazy (asincrono) I cambiamenti avvengono direttamente nella replica e poi vengono passati asincronamente.
Migliori performance ma un dato inconsistente può essere letto.
Dove
Master-slave le modifiche sono accettate solamente dal master, ciò comporta minore complessità
Peer to peer le modifiche sono accettate da tutte le repliche, grande complessità per la concorrenze e necessità di dover prevenire conflitti.
Ci sono varie tecniche per gestire una rete peer-to-peer: versioning, vector clock, gossiping, read repair
Combinando quando e dove si possono ottenere:
- Eager master-slave: RDBMS nei sistemi distribuiti
- Eager update anyware: poco usato
- Lasy master-slave: Mongo (CP system)
- Lasy update anyware: (AP system)
Se il sistema NoSql lo permette può venir lasciata la scelta all'utente:
- Una risposta veloce per minimizzare la latenza
- Una risposta consistente per prevenire dati inconsistenti
Slide20
Replica "Master e Slave"
I dati sono replicati attraverso più nodi
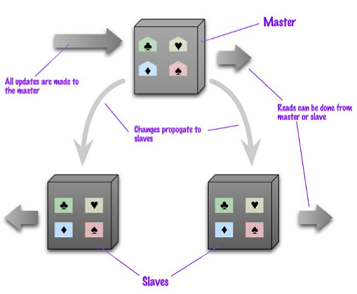
Un solo nodo è responsabile (master) di processare tutti gli update, gli altri nodi sono secondari.
La lettura può avvenire su tutti i nodi
Per applicazioni ad alta intensità di lettura
All'aumentare delle richieste di lettura -> più nodi slave
Si ha una "lettura-resiliente" infatti se il master è inraggiungibile, gli slave posso processare richeste di lettura
Uno slave può diventare velocemente un master
Il sistema viene limitato dalla quantità di update che il master riesce a processare
Il master può essere scelto manualmente o automaticamente
Peer-to-peer replication
Nessun master, ogni replica è uguale all'altra. Ogni nodo può gestire la scrittura e propagare l'update agli altri nodi

Nasce però il problema della consistenza. I client possono scrivere contemporaneamente su più nodi.
Quando c'è una scrittura, i nodi replicanti si coordinano per evitare i conflitti. Non tutti i nodi devono essere d'accordo, basta la maggioranza.
Shard e master-slave
In un sistema shard e master-slave, ogni dato shard è replicato. Ogni nodo può essere master per alcuni dati e slave per altri.
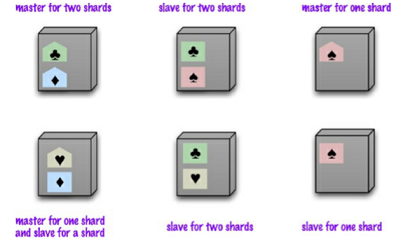
Shard e peer-to-peer
In questo sistema ogni shard è tipicamente prensete in 3 nodi, è il sistema usato di solito dai colum-family datacomum database
Ci possono essere problemi di consistenza

Consistency nei database
I database relazionali RDBMS assicurano una forte consistenza dei dati
I database distribuiti NoSql invece allentano il vincolo della consistenza, si passa quindi da "Strong Consistency" [ACID] a "Eventual Consistency"[BASE]
Viene affrontato nel teorema CAP - c'è da fare una scelta tra consistenza e disponibilità
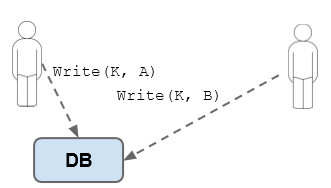
Consistenza in scrittura
[write-write conflict]
Problema: 2 utenti fanno un update dello stesso record nello stesso instante.
Ci potrebbere essere un problema in quanto in secondo update si base si un dato non consistente
Soluzioni
Approccio pessimistico: previene i conflitti con un semaforo prima dell'update
Approccio ottimistico: lascia che i conflitti possano succedere, e prova a risolverli se capitano.
Un esempio potrebbe essere un update condizionato, ogni client testa il valore che vorrebbe modificare; se è differente l'update fallisce
Consistenza in lettura
[read-write conflict]
Un utente legge nel mezzo di una scrittura di un altro utente.

La soluzione ideale: ACID, ovvero strong consistency.
Però NoSqlDatabase permettono atomic updates solamente a livello di singolo aggregato
Se abbiamo un update che implica diversi valori in più aggregati questo può portare a un time-slot in cui un cliente può leggere un valore inconsistente (inconsistency windows)
Transaction in NoSql non ci sono problemi se il DB è centralizzato, più complicato per sistemi distribuiti
Replication consistency
La consistenza tra le repliche ci assicura che il dato ha lo stesso valore quando viene lette da differenti nodi.
Eventuale consistenza significa che la scrittura si propagherà nella rete, quindi i dati passano nello stato di eventualemnte inconsistenza
Ci sono vari livelli di inconsistenza

Teorema CAP
C = consistency A = availability P = Partition Tollerance
Consistency
Dopo un update tutti i client del sistema vedono lo stesso dato
Un singolo database è sempre consistente, se occurrono diverse istante di scrittura e lettura il sistema deve trattarle in modo speciale
Availability
Se un nodo sta lavorando deve poter leggere e scrivere, quindi ogni richiesta deve essere processata
Partition Tollerance
Significa che il sistema deve continuare a funzionare anche se due insiemi di server vengono isolati.
Una connessione tra server fallita non dovrebbe pregiudicare l'intero sistema
Il teorema CAP afferma che un sistema non può avere tutte e 3 le proprietà, solamente 2 su 3 sono possibili
Nelle normali condizioni un sistema può essere sia disponibile che consistente. In presenza di una partizione, ciò non è più possibile. Un nodo deve decidere:
- continuare a processare le richieste del cliente, preservando la disponibilità alla consistenza
- non processare la richiesta, preservando la consistenza alla disponibilità
Riassumento
- AP - viola la consistenza
- CP - viola la disponibilità
- CA - sono disponibili e conistenti ma falliscono completamente se c'è una partizione
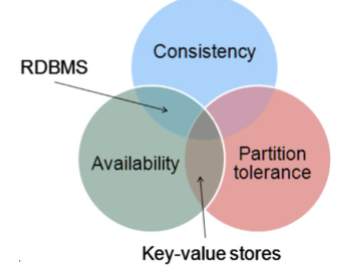
Un singolo server è sempre CA
Un sistema distribuito deve tollerare una partizione della rete.
Deve essere presa la decisione se scegliere la consistenza o la disponibilità
CP - consistenza e tolleranza alla partizione
Esempio. 2 utenti 2 nodi e 2 scritture

Consistenza forte, prima di ogni scrittura i nodi devono essere d'accordo sull'ordine delle scritture
In caso di partizionamento si perte la disponibilità in scrittura, in lettura è ancora possibile

Per poter aggiungere un pò di avalability si può avere una "master-slave" replicazione

Ora in caso di partizione il master può effettuare la scrittura ma i dati sullo slave in lettura saranno inconsistenti

AP - disponibilità e tolleranza alla partizione
usando un modello peer-to-peer replications, in caso di partizione si ha eventuale inconsistenza dei dati
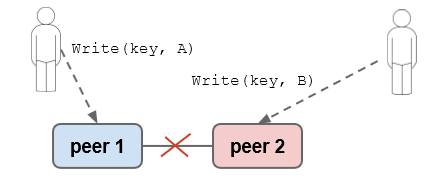
Si può quindi ovviare al problema con un soluzione intermedia: Quorums
Quorums
Nei sistemi peer-to-peer con la replica fattore N (n volte replicato il dato)
Quorum in scrittura: quando avviene una scrittura almento W repliche devono essere d'accordo
Avendo W > N/2 si ha la consistenza in scrittura
Esempio. 3 Nodi, W = 2 . Almeno 2 sui 3 nodi devono essere d'accordo con la scrittura
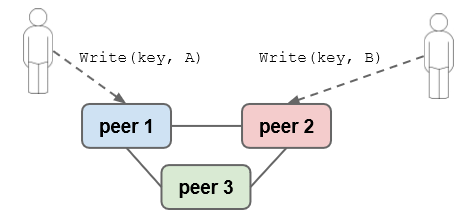
In caso di 2 scritture simultanee solamente 1 scrittura avrà la maggioranza
Slide21
Read quorum
Read quorum: R is the number of peers contacted for a single read
Assuming that each value has a timestamp (time of write) to tell the older value from the newer
For a strong read consistency: R + W > N [reader surely does not read stale data]
Example read quorum with R = 2 (R + W > N)
2 nodes contacted for read => the newest data returned
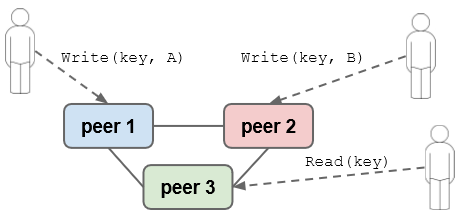
Relaxing Durability
Durability: when Write is committed, the change is permanent. In some cases, strict durability is not essential and it can be traded for scalability (write performance)
ex storing session data, collection sensor data
A simple way to relax durability: Store data in memory and flush to disk regularly, if the system shuts down, we lose updates in memory
BASE Concept
BASE: a (vague) term often used as contrast to ACID
● Basically Available
- The system works basically all the time
- Partial failures can occur, but without total system failure
● Soft state
- The system is in flux (unstable), non-deterministic state
- Changes occur all the time
● Eventual consistency
- The system will be in some consistent state
- At some time in future
Summary
- Sharding vs. replication
- Master-slave vs. peer-to-peer replication, a combination of sharding & replication
- Database consistency:
- Write/Read consistency (write-write & write-read conflict), replication consistency (also, read-your-own-writes)
● Relaxing consistency:
- CAP (Consistency, Availability, Tolerance to Partitions), Eventual consistency, BASE
- Quoras (write/read quorum), can ensure strong replication consistency; wide range of settings
Slide21b
Data distribution patterns
Solitamente i sistemi non relazionali non prevedono che siano rispettate le proprietà "ACID", si focalizzano infatti su altri aspetti:
- Bilanciamento tra disponibilità e consistenza
- Costi dell'hardware più contenuti, scalabilità orizzontale
- Resilienza: in caso di un guasto ad un nodo ci potrebbere essere sia continuità di servizio che la mancanza di perdita di dati
Architettura MongoDB
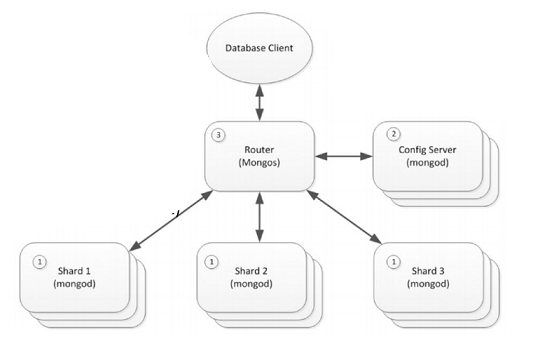
Il processo router (3) è resposabile per indirizzare le richiesta al giusto shard server.
Gli shard sono implementati con MongoDB database, non sanno il loro ruolo all'interno del server shared(1)
Il server di configurazione (2) contiene i metadata necessari per capire come i dati sono distribuiti i dati tra i vari shard
In MongoDB le collezioni sono formati da documenti JSON con attributi in comune
Le collezioni sono le unità elementari della distribuzione dei dati
Per dividere la collezione tra più shard bisogna scegliere una shared key
la shared key è un indice immutabile, composto da un unico campo o più campi ma che esiste in ogni documento della collezione
La shared key una volta scelta non si può più cambiare. la scelta della chiave influisce:
- Sulle performance e sulla scalabilità del sistema
- Influenza la strategia di sharding dei dati
Mongo sharding mechanism
Mongo partiziona i dati condivisi tra i vari shard in chunks
Ogni chunk ha 2 valori di riferimanto, uno basso ed uno alto,
un processo "balancer" gira in background per migrare chunk tra i vari shards e cercare di avere una distribuzione equa
Vantaggi dello sharding
MongoDB distribuisce il carico di letture/scritture attraverso i vari shard, facendo fare ad ognuno un pezzettino di lavoro di cluster
Il carico può essere scalato orizzontalmente su tutto il cluster aggiungendo dei nodi
Se l'attributo di riferimento di una singola query si riferisce ad un singolo shard mongo indirizza la richiesta a quello specifico shard
Un altro vantaggio dello sharding è la possibilità di aggiungere shard al crescere dei dati
Un cluster può avere maggior availability
- Ci possono effettuare parziali scritture / letture anche se qualche nodo della rete è guasto
- Letture o scritture dirette agli shard disponibili sono possibili
- Un cluster con shard configurati con Server Replica Set può continuare a processare letture e scritture per tutto il tempo che la maggior parte dei nodi è disponibile
Un database può avere un mix di shared e non shared collezioni
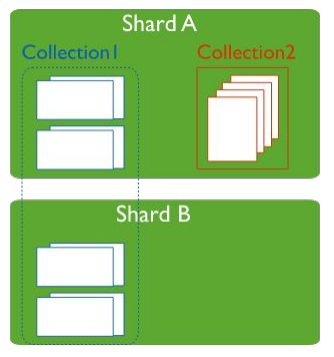
In questo esempio di cluser le shared collection sono distribuite tra i vari shard, mentre le collection non distribuite sono salvate direttamente in un unico shard.
Strategie per lo sharding
La distribuzione dei dati tra i vari shard può essere fatta:
Range base: ogni shard ha uno specifica serie di valori della shard key. é più efficente in caso di non monolitica changing shared keys
Hash base: è ideale per quelle chiavi che cambiano monotonicamente come _id o un timestamp
La configurazione hashed sharding richiede di computare una funzione di hash ogni volta che viene richiesto il campo shard key.
Ad ogni chank è assegnato un range di valori.
Mongo automaticamente risolve e computa gli hash quando risolve una query
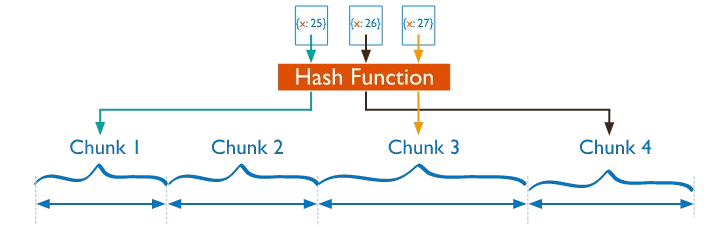
La distribuzione dei dati attraverso i valori di hash facilità la distribuzione, specialmente con quei dati monotoni.
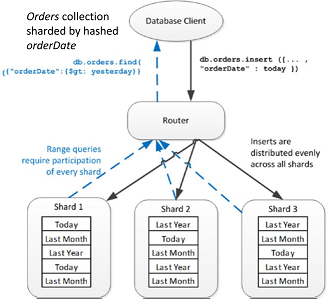
Una range query è poco probabile che punti ad un unico shard.
I documenti sono distribuiti uniformemente
Slide22
Ranged sharding
I dati sono divisi in base ad un range di valori della chiave shard
Ogni chunk è assegnato ad un serie di valori, mongo può indirizzare le operazioni quindi solamente agli shard che hanno quella chiave.
L'efficenza dipende dalla chiave.
Range-base sharding favorisce l'efficenza delle query che si risolvono processando solamente uno shard
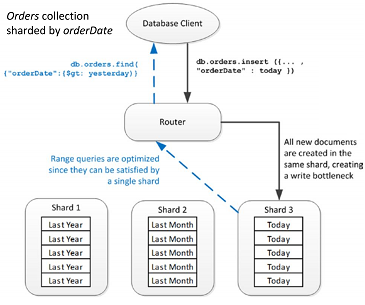
Una collezzione che usa x come shared key, che continua a far crescere gli elementi nello shard C
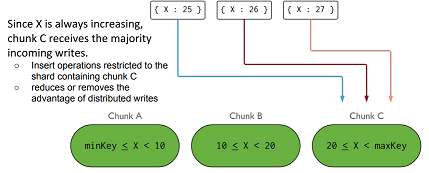
Per risolvere il problema basta usare una funzione di hash che distribuisce i dati tra i vari shard
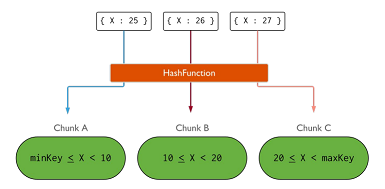
Zones - tag aware sharding
Permette dei ritocchi sulla distribuzione dei documenti tra i vari shard
Mongo permette di creare zone e determinare in quale shard quali documenti devono essere presenti
Una volta associati i documenti alle zone, un job di mongo si occuperà di migrare i dati
Le zone migliorano la vicinanza dei dati che sono magari sparsi tra vari datacenter
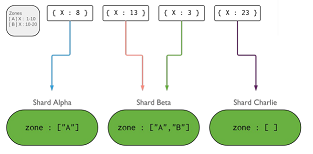
Usa dei campi della shardkey quando devi definire una nuovo range di valori per la zona da coprire
Le zone si usano solitamente:
- Isolare uno specifico sottoinsieme di dati
- Assicurarsi che i dati importanti per quella regione risiedono in quello specifico shard
- Rindirizzare i dati anche in base all'hardware di quello specifico shard
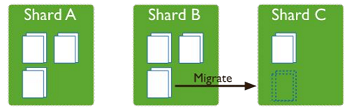
Balancer
è un processo che monitora il numero dei chunks presenti in ogni shark e migra i dati in modo da garantire una distribuzione equa degli stessi
Viene fatto partire quando il numero di chunk tra il più grande e il più piccolo supera una certa soglia
Viene fatto partire anche quando si aggiunge un nuovo nodo
Sharding è tipicamente combinato con la replicazione, ciò permette di avere availability e scalability
I dati sono replicati attraverso i vari nodi in replica
A replica set è definito come un gruppo di processi di mongoDB che mantengono gli stessi dati
Una replica set contiene un primary node e dei nodi secondari
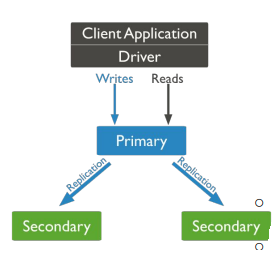
Il nodo primario accetta tutte le scritture, che sono poi propagate asincronamente
ai nodi secondari.
Oplog è una collezione (con un limite max) che tiene traccia
di tutti i record modificati.
Il nodo primario continua ad applicare le modifiche e aggiornare l'Oplog
I nodi secondari replicano poi le operazioni sui loro dataset

Sincronizzare i dati
I nodi secondari possono sincronizzare o replicare i dati
Ci sono 2 modi per sincronizzare i dati
- Sincronizzazione iniziale per popolare i nuovi nodi
- Replicazione avviene in continuazione
Elezioni nel Replica set
Un replica set può avere solamente un primario,
e di solito si usa una elezione per determinarlo
Le elezioni sono scatenate da:
- Un nuovo nodo che si aggiunge
- Quando creo il repliaca set
- Se il secondario perde connettività con il primario (non sente più l'heartbeat)
Se ad esempio il primario è irraggiungibile oltre una determinata soglia
, uno dei nodi secondari chiama un elezione per ripristinare
l'operativita'

Durante l'elezione del primario:
- Non vengono processate operazioni di scrittura
- Vengono processate query di lettura
Un nodo primario può scoprire di essere rimasto isolato, può quindi diventare secondario
Se un nodo che può comunicare con la maggior parte dei nodi può tenere una nuova elezione
Arbitri
In caso di un numero pari di attori, gli albitri permettono di
ottenere un voto a maggioranza.
Un arbitro
- Non salva nessun dato
- Risponde al ping ed alla richiesta di elezioni
- Non ha necessita di avere un hardware dedicato
Letture e scritture
Nei replica set si può configurare il livello di
"conferme" necessarie per le operazioni di scrittura e
specificare dove le richieste di lettura devono essere
indirizzate
Scrittura
Il write concerns è il numero di conferme
che un operazione di write deve avere per essere
considerata un completata con successo
- 1 solo il primario è necessario
- maggioranza la maggioranza degli attori deve rispodere positivamente
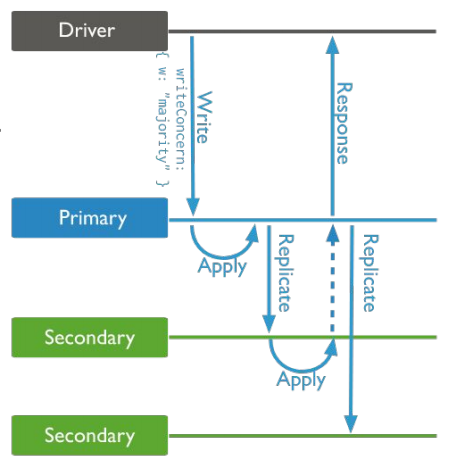
Lettura
Di solito le letture sono indirizzate al primario, volendo si può però
farle fare da un nodo secondario
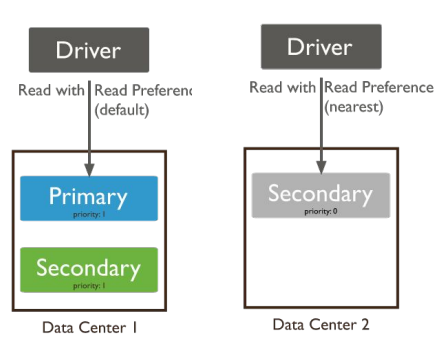
Le possibili preferenze di lettura:
- primary = operations read from the primary of the replica set
- primaryPreferred = operations read from the primary, but if unavailable,
operations read from secondary members
- secondary = operations read from the secondary members
- secondaryPreferred = operations read from secondary members, but if
none is available, operations read from the primary
- nearest= operations read from the nearest member (=
shortest ping time) of the replica set